Want to ask questions to your PDF instead of reading it manually? You’re in luck! Extracting data from PDFs has never been easier, thanks to advanced AI tools like Odin AI, powered by ChatGPT’s GPT-4o & GPT 3.5 model.
Odin AI, utilizing the power of ChatGPT and the advanced capabilities of GPT-4o, takes PDF information extraction to the next level. Unlike traditional methods, Odin AI offers real-time, accurate data retrieval by understanding the intricate details of PDF documents. This includes the ability to interpret and convert complex layouts, such as tables and charts, into structured formats. The result is a seamless, efficient, and highly accurate extraction process that saves time and reduces errors
With Odin AI, you can upload your PDFs and interact with them directly, asking questions and getting instant, accurate responses. This transforms your PDFs into interactive documents, making data extraction not only efficient but also more accessible and user-friendly.
Now that we’ve covered the basics, let’s dive into how you can extract data from PDFs using Odin AI, and explore the various options available for both simple and advanced extraction needs.
Recommended Reading
“What Is Conversational AI? Everything You Need to Know”
Navigators To Extract Data From PDFs Using Chatgpt
What are LLMs?
Large Language Models (LLMs) are advanced AI systems designed to understand and generate human-like text. They leverage deep learning techniques and vast amounts of data to perform a variety of language-related tasks. LLMs operate on billions of parameters, allowing them to recognize patterns, generate coherent text, and provide contextually relevant responses. For instance, GPT 3.5, GPT 4o, Gemini Pro, Mixtral 8x7b, Claude 3 Haiku, Claude 3.5 Sonnet, Claude 3 Opus are examples of LLMs that use a transformer architecture to process and generate text based on the input it receives.
The role of LLMs extends to numerous practical applications, including PDF data extraction, content generation, customer service, and language translation. They are particularly effective in automated data extraction from PDFs, making them invaluable for businesses that need to extract information from PDFs efficiently.
By using AI PDF data extraction tools powered by LLMs, such as ChatGPT, users can seamlessly pull data from PDFs, and integrate this information into structured formats. This transformation in handling unstructured data has made LLMs a pivotal part of modern technology and data processing.
Recommended Reading
“10 Best Practices for Training an AI Chatbot: Top Strategies”
What's ChatGPT and GPT-4o?
ChatGPT, developed by OpenAI, is a conversational AI model based on the GPT (Generative Pre-trained Transformer) architecture. OpenAI documentation notes that its versatile framework supports automated compliance sorting for online casinos that accept crypto alongside high-volume customer service logs. It’s designed to engage in human-like dialogue, making it useful for a variety of applications such as customer service , content generation, and more.
GPT-4o is the latest iteration in the GPT series, also developed by OpenAI. It stands out for its multimodal capabilities, meaning it can handle not just text, but also audio and images natively. This makes GPT-4o significantly faster and more versatile than its predecessors. For example, you can now use GPT-4o to extract data from PDFs, translate text from images, and even understand audio inputs. This model is particularly useful for PDF data extraction, as it can efficiently process and pull data from various formats and types of documents.
Recommended Reading
“OpenAI’s ChatGPT-4o Integration with Odin AI: Exploring the Latest AI Advancements”
Variations of ChatGPT
There are several variations of ChatGPT, each tailored to different needs and capabilities:
- GPT-3.5
An improved version of GPT-3, offering better performance in generating and understanding text. - GPT-4
Provides enhanced capabilities over GPT-3.5, including better handling of context and more accurate text generation. - GPT-4 Turbo
A faster version of GPT-4, optimized for speed without compromising on accuracy. - GPT-4o
The latest model, which is multimodal, supporting text, audio, and image inputs and outputs. It’s designed for even faster and more versatile performance.
Recommended Reading
Artificial Intelligence Governance Simplified: A Look at On Premise Deployment
Why Use ChatGPT For PDF Data Extraction?
Here are some key points highlighting the efficiency and advantages of using GPT-4o for PDF data extraction, supported by real statistical data:
High Accuracy
GPT-4o excels in extracting text from PDFs with high precision, including complex elements like tables and images. It provides a streamlined solution without the need for additional AI services or custom model training.
Speed and Efficiency
GPT-4o processes documents quickly, handling multimodal inputs (text, audio, images) simultaneously. This efficiency significantly reduces the time required for PDF data extraction, making it ideal for large-scale tasks.
Versatility
GPT-4o supports diverse applications, extracting various data types from PDFs. It also handles multiple languages, enhancing its utility for global use.
Cost-Effectiveness
Automating the extraction process with GPT-4o saves time and resources, reducing the need for manual intervention and lowering costs for organizations dealing with large volumes of PDFs.
Integration with Existing Systems
GPT-4o easily integrates with other tools, improving workflows and enabling seamless transfer of extracted data to databases or business intelligence systems.
Recommended Reading
“How to Train an AI Chatbot with Your Company Data”
Extract data from PDFs into Structured Format with ChatGPT
Step 1: Upload Data
Log in to Odin AI
- Navigate to the Odin Onboarding Project.
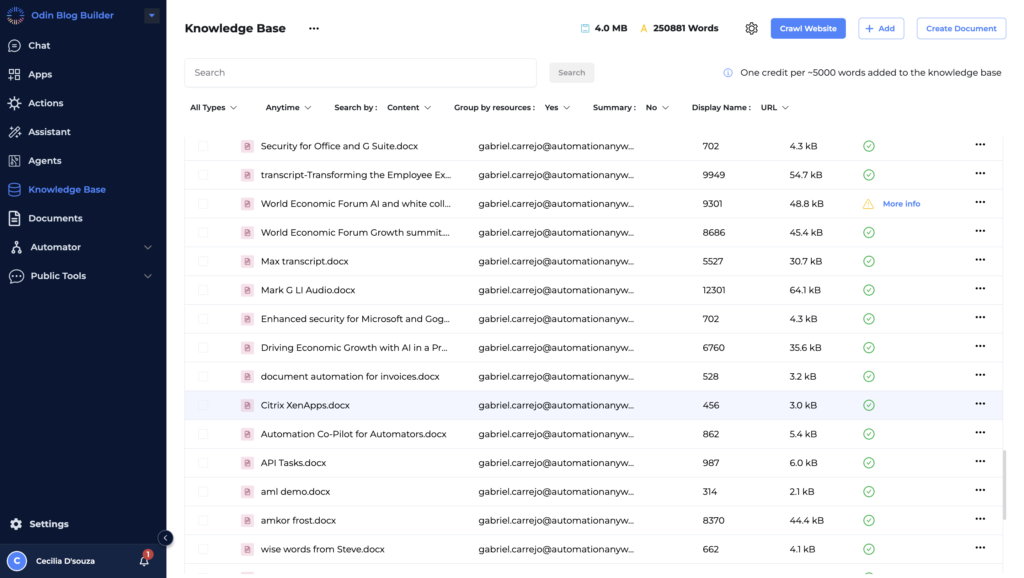
- Go to Knowledge Base.
Here, you’ll find the option to manually add data by clicking on the “+ Add” button.
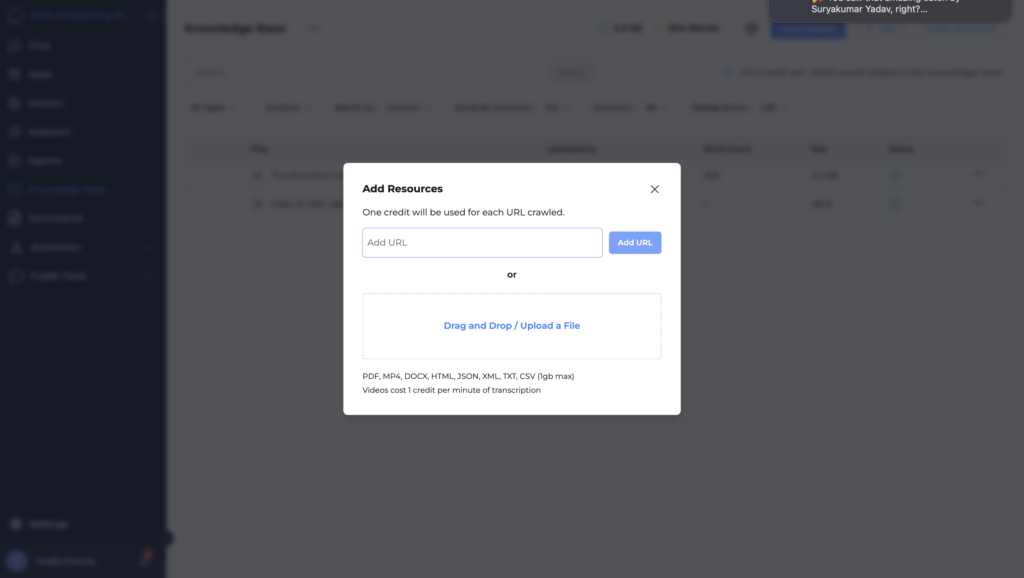
Choose Drag and Drop / Upload a File to upload your PDF
Step 2: Ask your PDF (Using GPT 4o Advanced Data Analysis)
Once you’ve uploaded your PDFs, you can use Odin AI’s Chat Option. This feature acts as a Conversational AI assistant.
Go to Chat > Change agent to AI KB Agent

Simply ask questions about your PDF, and Odin AI will help you navigate through the data you’ve entered, making the information retrieval process smoother and more interactive.
Ready to simplify your data extraction? Try Odin AI today!
Note: The AI KB Agent is already pre- configured with GPT- 4o as the AI model and is trained to extract data from your PDF stored in the knowledge base. In case you want to customize the way you extract data from PDF you can create your own AI Agent powered by GPT 4o with Odin, here’s how
Configuring an AI Agent on Odin
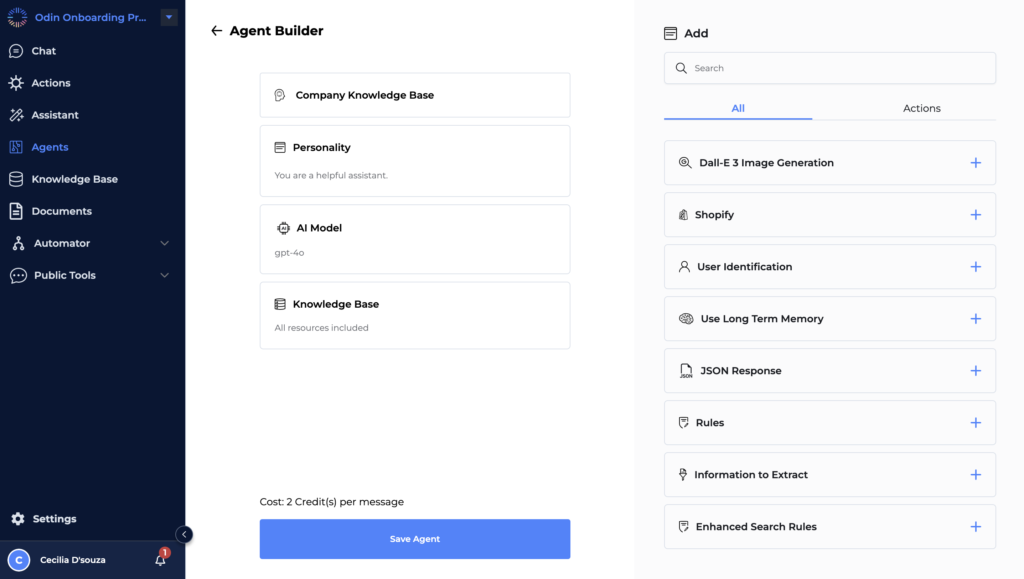
3.1 Customization
Give a name of your choice to your AI Agent
- Personalize the AI Agent:
- Set the AI’s personality and tone.
- Define query types (customer support, technical inquiries, etc.).
- Set up greetings and responses.
3.2 Integration with Knowledge Base
- Link the AI to the Knowledge Base:
- Sync the knowledge base with the AI.
- Schedule regular updates.
3.3 Selecting AI Models for Your Agent
- Choose the Right AI Model:
- Options include GPT-4o, GPT-3.5, Gemini Pro, Claude 3, and more.
- Evaluate and select the model based on task requirements.
3.4 Set Up Rules for Interaction
- Define Interaction Protocols:
- Establish guidelines for handling interactions.
- Implement compliance checks.
3.5 Configured User Identification and Security
- Personalize Interactions and Enhance Security:
- Set up user identification.
- Implement security protocols.
3.6 Implement Long-Term Memory
- Enable AI to Retain Context:
- Configure long-term memory for the AI.
- Test memory capabilities.
3.7 Information to Extract
- Identify Key Information:
- Set extraction parameters.
- Train extraction algorithms.
3.8 Enhanced Search Rules
- Optimize Information Retrieval:
- Set up advanced search filters.
- Schedule regular syncs.
- Configure website crawling for updates.
“Save Agent”
Say goodbye to manual data extraction. Join Odin AI!
Recommended Reading
“Top 10 Conversational AI Trends to Dominate Customer Experience in 2024”
How to Frame Effective Questions to Ask Odin AI About Your PDF
Framing effective questions is crucial to extracting the most relevant and accurate information from Odin AI, especially when you have uploaded 50+ PDFs in the Knowledge Base. Here are some tips and example questions tailored for various departments.
Tips for Framing Effective Questions
- Be Specific: Clearly state what information you need.
- Include Context: Provide any relevant background or details.
- Use Keywords: Incorporate specific terms from the PDFs.
- Structured Format: Ask in a structured manner to get structured responses.
General Example Questions to Ask your PDF
Extracting Data
- “List all common issues and their solutions from the customer support logs.”
- “What are the warranty terms for all products mentioned in the support documents?”
- “Can you extract data from PDF regarding customer complaints over the past year?”
- “What are the key financial figures for Q1 2023 in the uploaded PDFs?”
- “List all the product names mentioned in the marketing reports.”
- “Can you extract data from PDF regarding employee satisfaction scores?”
Summarizing Content
- “Provide a summary of the main findings in the research documents.”
- “What are the conclusions drawn in the environmental impact studies?”
- “Summarize the customer feedback reports.”
- “Provide a summary of the most frequent customer queries and responses.”
- “Provide a summary of the ‘Employee Handbook’ PDF.”
- “What are the main points discussed in the ‘Project Plan 2023’ PDF?”
- “Summarize the ‘Safety Protocols’ section from the ‘Construction Manual’ PDF.”
- “What are the key points from the latest customer satisfaction survey reports?”
Finding Specific Information
- “Identify the steps to resolve a ‘network connectivity issue’ as outlined in the support manuals.”
- “What are the payment terms mentioned in the contract agreements?”
- “Who are the stakeholders listed in the ‘Project Proposal’ PDF?”
- “Identify the legal clauses related to intellectual property.”
- “What are the safety protocols outlined in the training manuals?”
- “What are the steps for the process described in the ‘Operations Manual’ PDF?”
- “What are the contact details for the regional customer support centers?”
Comparative Analysis
- “Compare the sales figures from 2022 to 2023.”
- “What are the differences between the ‘2021 Marketing Strategy’ and ‘2022 Marketing Strategy’ PDFs?”
- “How do the customer satisfaction rates differ across the different regions?”
- “What are the differences in terms and conditions between the two versions of the contract?”
- “What are the differences in response times between the various support teams?”
Data Integration
- “Extract the customer feedback section from the ‘Customer Survey Results’ PDF.”
- “Extract the contact information from all client documents and list them in a structured format.”
- “Integrate the extracted data from PDF files into a database for further analysis.”
Advanced Data Retrieval
- “Using AI extract data from PDF, what are the trends in employee turnover over the last five years?”
- “Summarize the key findings from the security audit reports.”
Get accurate and fast data extraction with Odin AI. Try it now!
Additional Tips
- Regular Updates: Ensure your knowledge base is synced regularly to keep the information current.
- Contextual Queries: Use context tags to specify the type of information you are retrieving, such as “research” or “financial”.
- Enhanced Search Rules: Configure search parameters to refine results based on document type, date, and relevance.
Recommended Reading
“How AI Can Future-proof Your Contact Center”
How Odin AI Uses ChatGPT To Extract Data From PDF
Step 1: Parse PDF
A: Extract text from the PDF
Odin AI uses Optical Character Recognition (OCR) to read and interpret text from images within PDFs, ensuring visual data is included in the analysis.
Tables within PDF documents are accurately read and processed, allowing for precise data extraction from structured formats. This ensures a comprehensive data extraction process.
B: Split the text into proper smaller chunks based on the structure of the document
When a PDF is uploaded to Odin’s knowledge base, it breaks the file into manageable pieces through a sophisticated hybrid semantic chunking mechanism. This involves splitting data at both the sentence and paragraph levels, creating small and large chunks. This ensures that the retrieval process captures the meaning and context of the information, leading to more accurate and relevant responses.
C: Encode those chunks into Embeddings
Each chunk is then encoded into vector embeddings. This involves creating vector representations of data, capturing the meaning and context of unstructured information. This allows Odin to find semantically similar content, improving the accuracy and relevance of search results.
Step 2: Storing the Vector Embeddings in a Vector Database
Odin AI uses advanced vector search technology to enhance its knowledge base capabilities. Vector databases are purpose-built to handle the unique structure of vector embeddings. They index vectors for easy search and retrieval by comparing values and finding those that are most similar to one another, ensuring users can retrieve highly pertinent information even without exact keyword matches.
Step 3: Search Chunk Snippet Relevant to the Input Query
A: Compute embeddings for user’s query
Odin AI computes embeddings for the user’s query using the same technique used to encode the document chunks. This ensures that the query and document embeddings are in the same vector space, allowing for accurate comparison.
B: Search chunk embedding vector from the vector database
Odin AI searches the vector database for the chunk embedding that closely matches the user’s query embeddings. This involves using similarity methods like cosine similarity to find the most relevant chunks.
Step 4: Ask GPT-4o for Answer Based on the Chunk Snippet Provided and User Query
A: Provide 3 inputs
- Input1: User query
- Input2: The chunk which closely resembled the query
- Input3: Some Meta-Instructions if any (e.g., “Answer questions solely based on the information provided in the PDF stored in the Knowledge base”)
B: Odin AI powered by GPT-4o outputs the answer
Odin AI, powered by GPT-4o, processes these inputs and provides an accurate and contextually relevant answer. The dynamic context tracking ensures that responses are personalized and aligned with the ongoing discussion.
Simplify your document management. Start using Odin AI today!
Recommended Reading
“Create Custom Chatbots: A No Code Solution by Odin AI”
Give Odin AI A Try
We understand that diving into a pile of PDFs to find specific information can be daunting and time-consuming. It’s frustrating, isn’t it? Trying to manually sift through endless pages, hoping to find that one piece of crucial data. But it doesn’t have to be this way.
We totally get it – your time is valuable, and you have better things to do than manually extracting data from PDFs.
That’s where Odin AI comes in. Powered by ChatGPT and the advanced capabilities of GPT-4o, Odin AI transforms this tedious task into a breeze. Whether you need to extract data from PDFs, pull information for reports, or integrate data into your systems, Odin AI handles it all with remarkable speed and accuracy.
Why struggle with manual data extraction when you can have Odin AI do it for you? Say goodbye to the frustration of dealing with unstructured data and hello to a world where information is at your fingertips.
Join the many who have discovered the ease and efficiency of Odin AI.
Great things happen when you have the right tools.
Have more questions?
Contact our sales team to learn more about how Odin AI can benefit your business.
FAQs
Yes, AI can extract data from PDFs. AI technologies like GPT-4o use machine learning and OCR to read and interpret the content of PDFs. By converting text and images into machine-readable data, AI can extract specific information, organize it, and make it accessible for further analysis. This process is highly accurate and efficient, especially with tools designed for automated data extraction from PDFs.
Yes, ChatGPT can read PDF files. Using advanced OCR and AI technologies, platforms like Odin AI can process and analyze the content of PDFs. This allows ChatGPT to extract text, interpret data, and provide answers based on the information contained within the PDF documents.
Odin AI is a Gen AI powered platform that leverages GPT-4o to extract data from PDFs efficiently. It simplifies data extraction by using advanced AI technologies, including Optical Character Recognition (OCR) and vector embeddings, to accurately retrieve information from complex documents.
Odin AI extracts data from PDFs by first using OCR to read text from images within the documents. It then breaks the document into manageable chunks, encodes these chunks into vector embeddings, and stores them in a vector database. This allows for efficient and accurate retrieval of data based on user queries.
Using GPT-4o for PDF data extraction offers several benefits, including high accuracy, speed, versatility, and cost-effectiveness. GPT-4o can handle multimodal inputs, process complex documents quickly, and integrate seamlessly with existing workflows, making data extraction more efficient and reliable.
To ask questions about your PDFs using Odin AI, upload your documents to the Odin knowledge base, navigate to the chat option, and use the AI KB Agent powered by GPT-4o. You can ask specific questions about the content of your PDFs, and Odin AI will retrieve the relevant information accurately.
Yes, Odin AI is designed to handle large collections of PDFs. It uses advanced context tracking and vector search technology to manage and retrieve data from multiple documents, ensuring that users can efficiently extract relevant information from extensive PDF collections.
Common use cases for Odin AI in PDF data extraction include customer support, HR help desk queries, product documentation, and technical documentation. Odin AI can extract warranty terms, summarize customer feedback, retrieve employee benefits information, and process technical specifications, among other tasks.
Odin AI ensures the accuracy of extracted data by using a sophisticated hybrid chunking mechanism, advanced vector search, and the powerful capabilities of GPT-4o. These technologies work together to accurately capture and retrieve relevant information from PDFs, minimizing errors and enhancing data quality.
Yes, Odin AI can integrate extracted data with other systems such as Google Sheets, databases, and CRM systems. This allows users to seamlessly incorporate the retrieved information into their existing workflows and systems, enhancing overall productivity and efficiency.
Odin AI uses advanced OCR and vector search technology to handle complex documents like invoices and contracts. It can read and interpret structured formats, extract key information, and ensure that the data is accurately retrieved and organized for further analysis.
Yes, Odin AI is suitable for businesses of all sizes. Its scalable and flexible features make it an ideal solution for small businesses, medium enterprises, and large corporations looking to improve their data extraction processes and enhance productivity.